Advertisement
SmolAgents was built with a simple idea: lightweight, inspectable AI agents that can perform real-world tasks using language. They're small, easy to understand, and capable of following instructions. But up until now, they've been missing one major piece—perception. They couldn't see what they were working on.
Instead, they relied on structured inputs or scripted conditions, meaning every task had to be planned carefully. That limitation has just been lifted. By giving them vision, we've opened up a new level of autonomy, making these agents more practical and responsive in unpredictable environments.
Originally, SmolAgents operated in a logic-only world. They could plan actions, respond to goals, and work through problems step-by-step—but they had no idea what the environment looked like. Whether it was a website, an app, or a document, the agent had to be told exactly what to expect. Any change in layout or interface could throw it off completely. That lack of perception limited how flexible and robust the agents could be.
Now that vision has been introduced, the agent's experience of the world changes. Instead of waiting for structured instructions, it can look at an image—a screenshot of a web page—and decide what to do next based on what it sees. It can identify buttons, detect forms, read labels, and verify whether its actions produced the right result. This brings awareness that wasn't possible before and does so without needing to overhaul the agent's design.
The approach remains small and accessible. SmolAgents don't suddenly become massive black-box models. They stay light, fast, and transparent. What changes is their ability to interpret the environment through images and adapt on the fly?
To see, SmolAgents uses a vision-language model—one that takes an image as input and responds with text. The process starts with the agent capturing a screenshot of its current environment. It then asks the model questions like "What buttons are visible?" or "What text is on this section of the page?" The model answers with a structured response that the agent can reason over.

This feedback loop allows the agent to understand what is possible and what has changed. For example, if it submits a form and sees a confirmation message, it knows the task was successful. If an error appears, it can try a different step. This responsiveness makes the system much more reliable.
The other advantage is flexibility. Without needing a hardcoded layout or predefined workflow, the agent can navigate different environments with minimal setup. Whether it's a new software interface or an updated website, it uses sight to figure things out. That kind of flexibility would be impossible in the old, blind model.
It also simplifies development. Instead of writing detailed mappings of every UI element, you let the agent look and reason. That cuts down on engineering effort and makes building for unknown or changing interfaces easier.
Adding visual input to SmolAgents isn’t just a cool trick—it solves real problems. First, it removes the fragility that came from hardcoded assumptions. Before, if a button moved or changed labels, the agent might fail. Now, it can visually identify that button and carry on.
Second, it opens the door to faster iteration and broader usability. Developers don't need to know every user interface detail in advance. The agent can start with general instructions and learn from what it sees. That makes it easier to automate tasks across multiple tools, even if those tools don't expose APIs or have structured layouts.
Another key benefit is traceability. Because the agent bases decisions on images and model responses, it’s possible to track its reasoning step-by-step. You can see exactly what it saw, what it asked, and what it decided. That kind of transparency is helpful for debugging, improvement, and trust.
From a broader perspective, this move reflects a shift toward more grounded AI—systems that don't just think in the abstract but respond to the world around them. It brings SmolAgents closer to how humans interact with digital environments: observing, interpreting, and deciding based on what's visible.
It's not about making them all-knowing or giving them complex reasoning powers. It's about giving them enough awareness to function more smoothly in practical settings. That's what makes this update useful, not just interesting.
This step sets the stage for deeper improvements. One direction is continuous observation—where agents don't just take one image and act but track changes over time. That can lead to better timing and more nuanced decisions, especially in apps with animations, state changes, or dynamic updates.

Another path is visual memory. If a SmolAgent remembers what the screen looked like earlier, it can compare past and present views to track progress or spot changes. That helps detect errors, loop steps, or adapt to shifting tasks.
Over time, vision may combine with other input—text, API data, or audio—to expand understanding. But even on its own, vision matters. It’s the difference between guessing and knowing.
The challenge is keeping the framework small and practical. SmolAgents’ simplicity works for solo developers and small teams. Vision shouldn't make them bloated or hard to grasp. So far, that balance is holding.
Ethics and privacy will matter, too. Letting an agent view interfaces raises concerns. Developers must be clear about what's seen, where it goes, and how it's used—especially in finance, education, or healthcare.
These are design and policy questions, not technical limits. What’s clear now is that SmolAgents with sight are a more grounded kind of AI—able to observe the world, act with logic, and stay within clear boundaries.
SmolAgents began as a simple experiment to achieve more with less. With sight, they've become smarter and more capable—able to see, understand, and respond to what's in front of them. This doesn't make them flawless, but it does make them far more useful. They can now interact with dynamic environments in a practical, reliable way. It proves that small models when equipped with the right tools, can handle real-world tasks effectively. Sight isn't just an upgrade—it's a meaningful shift.
Advertisement

How using open-source AI models can give your startup more control, lower costs, and a faster path to innovation—without relying on expensive black-box systems
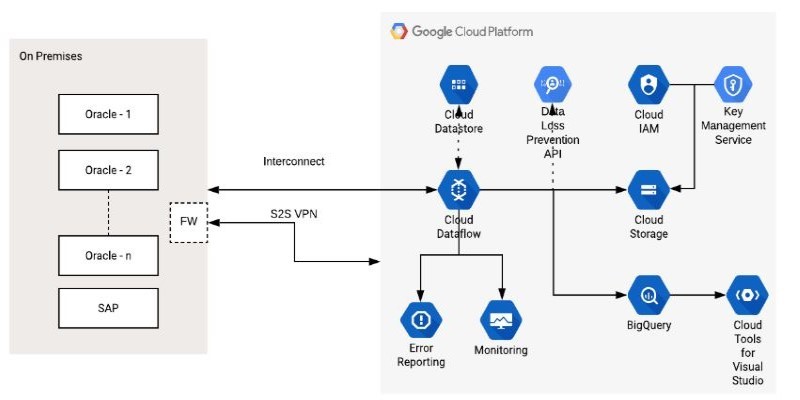
How the Google Cloud Dataflow Model helps you build unified, scalable data pipelines for streaming and batch processing. Learn its features, benefits, and connection with Apache Beam

How to approach AI implementation in the workplace by prioritizing people. Learn how to build trust, reduce uncertainty, and support workers through clear communication, training, and role transitions
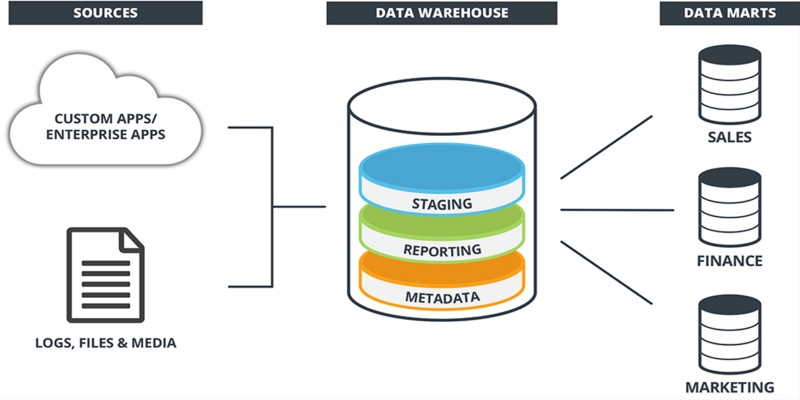
Learn what a data warehouse is, its key components like ETL and schema designs, and how it helps businesses organize large volumes of data for fast, reliable analysis and decision-making

What's changing inside your car? A new AI platform is making in-car assistants smarter, faster, and more human-like—here's how it works

What's fueling the wave of tech layoffs in 2025, from overhiring during the pandemic to the rise of AI job disruption and shifting investor demands

Can a small language model actually be useful? Discover how SmolLM runs fast, works offline, and keeps responses sharp—making it the go-to choice for developers who want simplicity and speed without losing quality

Is the future of U.S. manufacturing shifting back home? Siemens thinks so. With a $190M hub in Fort Worth, the company is betting big on AI, automation, and domestic production

Ready to make computers see like humans? Learn how to get started with OpenCV—install it, process images, apply filters, and build a real foundation in computer vision with just Python

Learn how to install, configure, and run Apache Flume to efficiently collect and transfer streaming log data from multiple sources to destinations like HDFS

Achieve lightning-fast SetFit Inference on Intel Xeon processors with Hugging Face Optimum Intel. Discover how to reduce latency, optimize performance, and streamline deployment without compromising model accuracy

Google risks losing Samsung to Bing if it fails to enhance AI-powered mobile search and deliver smarter, better, faster results