Advertisement
Training a vision-language model (VLM) to follow human preferences is no longer a stretch — it's quickly becoming standard practice. The aim isn't just more accurate output but responses that feel more natural, more useful, and more in tune with what people expect. This is where preference optimization comes in. Instead of aiming for a single correct answer, it teaches the model to favor the kind of output humans find more helpful. When presented with two possible responses, the model learns to choose the one people tend to prefer.
To support this, TRL — short for Transformer Reinforcement Learning — steps in with a set of tools that simplify the process. It packages the mechanics of preference training, reinforcement learning, and reward modeling into something more practical and accessible.
TRL doesn’t train your base model from scratch. It tunes it using feedback, nudging it toward choices that reflect human-like preferences. You start with a base VLM — say, one that can caption images or answer questions about pictures — and use TRL to improve how well those outputs align with what people prefer to see or read.
It brings together several tools:
What makes TRL so relevant for VLMs is that it doesn't just train for correctness; it also trains for relevance. It trains for quality as judged by humans. And with vision-language models, where responses are often subjective (like describing a photo or making inferences), this nuance matters.
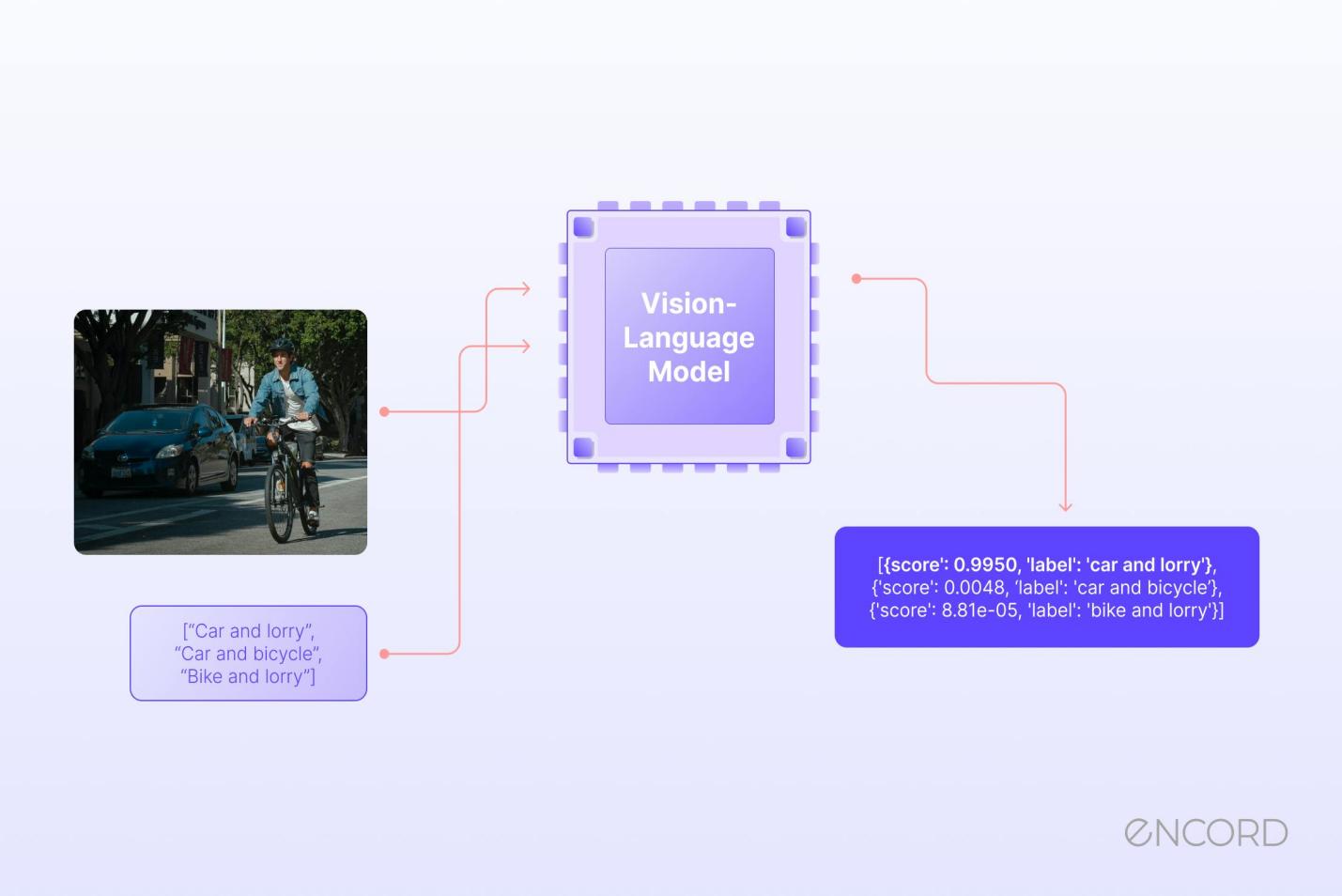
Everything starts with a pre-trained VLM. This could be a model like Flamingo, BLIP, or LLaVA — something that can understand and generate responses based on both text and visual inputs. At this stage, the model is pretty good at its tasks, but it doesn’t always produce answers that reflect human-like judgment or subtle context clues.
Now comes the data. It's not the usual training data but comparison data. This involves showing two model responses to human annotators and asking them which one they prefer. It's not about being right or wrong — it's about which response feels more natural, informative, or relevant.
This dataset becomes the foundation for training a reward model. Each comparison gives a signal: response A is better than response B.
The reward model learns to predict which outputs humans are likely to prefer. It’s trained to score responses, not to generate them. You feed it examples where humans have picked one option over another, and it learns to replicate that preference signal.
This model becomes the judge for the next stage. Instead of asking a person every time, the reward model acts as a stand-in to evaluate how well the main model is doing.
Now, it's time to optimize. Using TRL's PPO implementation, you tune the base model based on the scores given by the reward model. PPO is a reinforcement learning algorithm that helps balance exploration and stability — in short; it nudges the model toward preferred responses without throwing off what it already knows.
This stage doesn’t require new images or questions — it uses the same types of inputs but aims to get better outputs over time. Each generated response is scored by the reward model, and PPO updates the model accordingly.
Once preference optimization is complete, it's time to test. This isn't just a one-off benchmark — it's a process. Human evaluations often remain the gold standard here, but you can also use synthetic evaluations or ranking metrics. The key is to look at whether responses feel more aligned with human intuition, not just accuracy scores.
Vision-language tasks are rich but fuzzy. There’s often no single right answer. If you ask a model, “What’s happening in this photo?” it might say, “A child is playing soccer,” or “A boy kicks a ball in the park.” Both are technically right, but one may feel more human-like. Preference optimization teaches models of these subtle preferences. It rewards choices that sound more natural, are better phrased, or show more awareness of the scene.
Visual question answering might help the model learn when to be more detailed or when a brief answer is fine. Captioning teaches phrasing that mirrors how people actually talk about photos. In multimodal dialogue, the model responds in a way that feels conversational, not robotic.
The outcome is smoother, more helpful interactions. Not because the model learned more facts but because it learned how people like things to be expressed.
One of the strongest points in TRL’s favor is its simplicity. Under the hood, preference optimization is technical — it involves gradient updates, feedback loops, and reward modeling. But TRL puts this in a format that makes the workflow easier to implement.
It lets you:
And because it's integrated with Hugging Face, you can easily swap in different VLMs or try out variations without needing to rebuild the pipeline each time.
Preference optimization isn’t about making vision-language models smarter in the traditional sense. It’s about making them feel more helpful, more relatable, and more in line with how people actually communicate.
TRL doesn't invent this idea — but it makes it accessible. Providing tools for reinforcement learning with human feedback lets developers and researchers focus more on tuning model behavior and less on infrastructure. And in a space where every bit of user alignment counts, that makes a difference.
Advertisement
How to use ChatGPT for Google Sheets to automate tasks, generate formulas, and clean data without complex coding or add-ons

How using open-source AI models can give your startup more control, lower costs, and a faster path to innovation—without relying on expensive black-box systems
An AI startup has raised $1.6 million in seed funding to expand its practical automation tools for businesses. Learn how this AI startup plans to make artificial intelligence simpler and more accessible

How does an AI assistant move from novelty to necessity? OpenAI’s latest ChatGPT update integrates directly with Microsoft 365 and Google Workspace—reshaping how real work happens across teams
Nvidia NeMo Guardrails enhances AI chatbot safety by blocking bias, enforcing rules, and building user trust through control
Looking for the best way to merge two lists in Python? This guide walks through ten practical methods with simple examples. Whether you're scripting or building something big, learn how to combine lists in Python without extra complexity

Learn the top 5 AI change management strategies and practical checklists to guide your enterprise transformation in 2025.

Nvidia is set to manufacture AI supercomputers in the US for the first time, while Deloitte deepens agentic AI adoption through partnerships with Google Cloud and ServiceNow

Accelerate AI with AWS GenAI tools offering scalable image creation and model training using Bedrock and SageMaker features

Writer unveils a new AI platform empowering businesses to build and deploy intelligent, task-based agents.

Can small AI agents understand what they see? Discover how adding vision transforms SmolAgents from scripted tools into adaptable systems that respond to real-world environments

AI-first devices are reshaping how people interact with technology, moving beyond screens and apps to natural, intelligent experiences. Discover how these innovations could one day rival the iPhone by blending convenience, emotion, and AI-driven understanding into everyday life