Advertisement
Data today arrives faster and in larger volumes than ever, pushing older processing systems beyond their limits. Many organizations struggle to keep up, juggling separate tools for real-time streams and periodic batch jobs. The Google Cloud Dataflow model was designed to change that, offering a simpler way to handle both within one consistent framework.
Rather than worrying about infrastructure or writing duplicate logic, developers can focus on what really matters — the data itself. With its flexible design and seamless integration of streaming and batch, the Dataflow model has redefined how teams approach large-scale data processing.
The Google Cloud Dataflow model is a programming approach for defining data processing workflows that can handle both streaming and batch data seamlessly. Unlike older systems that treat real-time and historical data as separate challenges, Dataflow unifies both into one consistent model. It powers Google Cloud’s managed Dataflow service and is based on Apache Beam, which brings the same concepts to open-source environments.
At its heart, the model represents data as collections of elements that are transformed through operations called pipelines. Pipelines describe how to process and move data without dictating how the underlying system executes the work. This separation lets developers focus on the logic while the platform manages scaling, optimization, and fault tolerance.
Dataflow pipelines don’t need to wait for all data to arrive before starting. They can process incoming data live while also working through historical backlogs, making it easier to handle hybrid workloads. For example, a single pipeline can compute live web analytics and also reprocess months of older logs in the same workflow.
The Dataflow model relies on three main ideas: pipelines, transformations, and windowing.
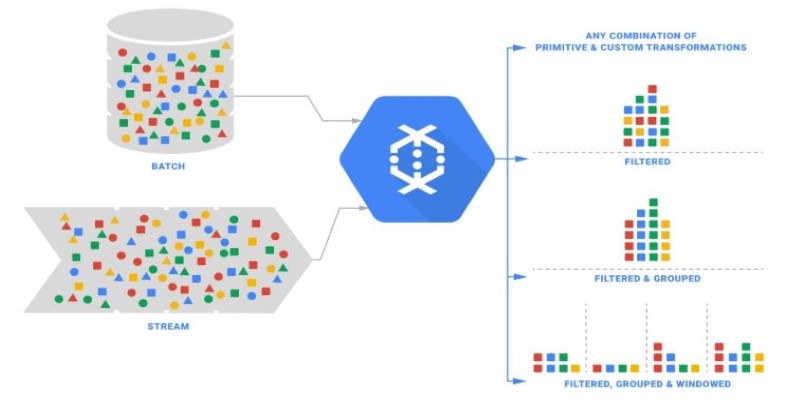
A pipeline is the full description of a processing job, from reading data to transforming it and writing results. Data can come from cloud storage, databases, or streaming systems like Pub/Sub, and it can be sent to a variety of sinks.
Transformations are the steps within a pipeline. These include filtering records, grouping by key, joining datasets, or computing summaries. You can chain multiple transformations to create workflows of any complexity, all while letting the system handle how work is distributed and parallelized.
One of the model’s most innovative aspects is windowing and triggers. Since streaming data arrives over time and often out of order, it’s useful to group data into logical time windows — such as per minute, hour, or day — for analysis. Triggers decide when results for a window are produced, which could be as soon as data arrives, at fixed intervals, or after waiting for late records.
When a pipeline runs, the Dataflow service distributes work across many machines automatically. Data is divided into partitions, each processed by a worker. The system handles retries, failures, and scaling without requiring the developer to write special logic. This makes it possible to write simple code while still achieving high throughput and reliability.
The Google Cloud Dataflow model eliminates the long-standing gap between batch and streaming data processing. Previously, teams built separate systems for real-time analytics and periodic batch reports, which often led to duplicated logic and inconsistent results. The Dataflow model removes this divide by treating both as forms of processing a collection of elements, letting the same pipeline logic work for both live and historical data.
This unified model saves time and reduces errors, since developers only need to write and maintain one pipeline. For example, a pipeline that calculates daily sales totals in real-time can also be reused to recompute months of past sales data when needed. This is especially useful when data arrives late or needs to be corrected.
The declarative style of the model is another strength. Developers describe what transformations to perform, without worrying about how the work is distributed or scaled. This makes pipelines easier to maintain and adapt as requirements change. As data grows, the underlying infrastructure automatically scales out, while ensuring correct and complete results.
Using Google Cloud’s managed Dataflow service removes the burden of managing infrastructure. The service automatically provisions resources, monitors jobs, and adjusts to workload changes. This frees developers to focus on pipeline logic rather than managing servers or tuning clusters.
The Dataflow model is closely tied to Apache Beam, the open-source project that implements the same programming concepts. Beam allows developers to write pipelines that run on multiple execution engines, such as Google Cloud Dataflow, Apache Spark, or Apache Flink.

Beam serves as the SDK layer, while Google Cloud Dataflow is a fully managed runner designed for Google’s infrastructure. Developers can use Beam’s SDKs in Java, Python, or Go to define pipelines, then choose the best environment to execute them. This keeps pipelines portable while still letting teams benefit from the performance and scaling of the managed Dataflow service.
Portability is particularly valuable for organizations working in hybrid or multi-cloud environments. Pipelines written with Beam can move between platforms without major changes. While Google Cloud Dataflow offers a fully managed experience, Beam ensures that your logic isn’t tied to a single provider.
The Google Cloud Dataflow model offers a clear, unified way to process both streaming and batch data without having to build separate systems. By focusing on describing transformations and letting the platform manage execution, it simplifies development and operations. The model’s ability to handle both real-time and historical data in a single pipeline reduces duplication and improves consistency. With Apache Beam enabling portability, teams can write once and run anywhere, while still enjoying the benefits of Google Cloud’s managed Dataflow service. For anyone working with large or fast-moving datasets, the Dataflow model is a practical and effective solution.
Advertisement

Discover the best Artificial Intelligence movies that explore emotion, identity, and the blurred line between humans and machines. From “Her” to “The Matrix,” these classics show how AI in cinema has shaped the way we think about technology and humanity

How benchmarking text generation inference helps evaluate speed, output quality, and model inference performance across real-world applications and workloads
Learn how integrating feature selection into model estimation improves accuracy, reduces noise, and boosts efficiency in ML

How IBM and L’Oréal are leveraging generative AI for cosmetics to develop safer, sustainable, and personalized beauty solutions that meet modern consumer needs

Get full control over Python outputs with this clear guide to mastering f-strings in Python. Learn formatting tricks, expressions, alignment, and more—all made simple

AI saved Google from facing an antitrust breakup, but the trade-offs raise questions. Explore how AI reshaped Google’s future—and its regulatory escape
How does Docmatix reshape document understanding for machines? See why this real-world dataset with diverse layouts, OCR, and multilingual data is now essential for building DocVQA systems

Know how AI transforms Cybersecurity with fast threat detection, reduced errors, and the risks of high costs and overdependence

Learn how to compare two regression models with statistical significance for accuracy, reliability, and better decision-making

Writer unveils a new AI platform empowering businesses to build and deploy intelligent, task-based agents.

Is the future of U.S. manufacturing shifting back home? Siemens thinks so. With a $190M hub in Fort Worth, the company is betting big on AI, automation, and domestic production

How a machine learning algorithm uses wearable technology data to predict mood changes, offering early insights into emotional well-being and mental health trends