Advertisement
Running AI models is no longer just a technical puzzle—it’s a question of time, budget, and ease. For many developers and researchers, the real bottleneck isn’t training a model but figuring out how to deploy it without spinning up expensive GPU servers or wrangling cloud infrastructure. That’s where serverless GPU inference comes in.
Hugging Face now offers a way to run powerful models on demand without any backend setup. It's a shift that matters, especially for smaller teams and solo builders who want performance without the complexity. Just upload a model, call an API, and get results—fast, simple, and scalable.
Before serverless options, serving GPU-based models involved renting powerful cloud machines and setting up custom environments. That process required manual scaling, monitoring, and resource cleanup. Even small workloads could become expensive when GPU instances sat idle.
With serverless GPU inference, you don’t need to keep machines running. Compute is provisioned only when a request is made. Once the model runs, the environment shuts down. Hugging Face now offers this functionality straight from its model hub. Upload a model, and it's deployable instantly via a secure API backed by dynamic GPU computing.
Models are run inside containers preloaded with the necessary libraries, such as PyTorch, TensorFlow, or JAX. When an API call is made, the system spins up a container, loads the model, runs inference, and returns results. The cold start time is kept to a minimum, and no manual setup is involved. The entire process happens automatically and scales with usage.
This setup is especially useful for developers who want to test ideas quickly or scale a project without managing the underlying hardware. Even models using complex pipelines, such as those for text generation or image transformation, can be served in this way.
The flexibility of serverless GPU inference stands out. Whether your project has sporadic usage or requires handling spikes in traffic, the infrastructure adjusts automatically. There's no need to guess usage patterns or worry about overprovisioning.

Serverless deployment benefits any model that relies on GPU acceleration for speed, like vision transformers, speech models, or large-scale language models. Inference times drop, and you only pay for what you use. This is helpful when cost management is critical, such as in academic environments or side projects.
Each endpoint in Hugging Face's system supports live monitoring and version control. You can track usage, errors, and latency from a single dashboard. The interface is simple yet gives enough control to customize how models are called and what format results are returned in.
For high-traffic use cases, batching and caching are supported. This allows for cost reduction and faster response times. Small models remain cheap to serve, and larger models, while more resource-heavy, are still more affordable in this on-demand format than persistent hosting.
The platform also offers Python-based handlers, giving advanced users more control over pre- and post-processing. This helps support more specialized use cases without requiring a separate hosting system. Whether for quick prototypes or production-grade endpoints, the cost-performance balance is more sustainable than traditional deployments.
One advantage Hugging Face offers is its deep model hub integration. Once you’ve fine-tuned or uploaded a model, you can serve it as an endpoint in a few steps. Metadata included in the repository guides the system on how to interpret inputs and generate outputs.
Popular pipelines—like text-classification, text-generation, or image-to-text—are supported automatically. Many models can run without writing custom inference code. For those that need more, Hugging Face lets you include a handler.py file for custom logic, letting you tailor input-output handling precisely.
Beyond the deployment itself, Hugging Face offers tools for sharing and collaboration. You can keep an endpoint private, share it with your team, or make it public. Teams can manage models together, assign access rights, and even monitor joint usage stats.
The model endpoints also connect easily with Hugging Face Spaces and Gradio apps. This makes it easy to build user-facing demos or internal testing tools backed by live inference. The user interface, the model, and the deployment are all connected in one environment, simplifying the full pipeline.
Security is handled through API keys and access control settings. You can restrict who can use your endpoint and limit usage based on traffic. This is helpful when releasing early-stage features or inviting feedback from select users before a full launch.
Logs, metrics, and analytics are built into each deployment. This helps identify performance issues, understand usage trends, and debug errors, all from the Hugging Face interface or external monitoring tools if preferred.
Serverless infrastructure has changed how developers build applications. Bringing that model to AI—especially GPU-heavy models—removes barriers and speeds up development. Renting full-time GPU instances just to test or serve a model is becoming unnecessary.

This format fits researchers' testing ideas, app developers building AI features, and teams adding ML to products. There's less time spent setting up or scaling systems. You focus on the model and what it delivers—not the infrastructure behind it.
Hugging Face supports this by combining model hosting, versioning, serving, and visualization in one place. Even small teams can stay productive without juggling services.
Serverless GPU inference may grow into edge deployments, private models, and mobile endpoints. The core remains: run models when needed, scale automatically, and hide the hardware layer. It’s shaped by developer needs, not enterprise processes.
Simplified deployment reduces technical hassle and makes AI more reachable. Developers can focus on ideas and let the platform manage GPU scaling.
Serverless GPU inference brings Hugging Face users a better way to serve models: one that removes infrastructure tasks lowers cost, and scales easily. Instead of configuring servers or dealing with idle GPUs, you upload a model and serve it on demand. This works well whether you're testing a feature, running a research tool, or supporting a production app. Hugging Face ties everything together, making deployment, versioning, monitoring, and sharing part of the same flow. With fewer barriers, more developers can build real-world AI tools quickly and at a lower cost. This approach makes modern inference feel simple, fast, and within reach.
Advertisement

Discover the best Artificial Intelligence movies that explore emotion, identity, and the blurred line between humans and machines. From “Her” to “The Matrix,” these classics show how AI in cinema has shaped the way we think about technology and humanity

What's changing inside your car? A new AI platform is making in-car assistants smarter, faster, and more human-like—here's how it works
Speed up your deep learning projects with NVIDIA DGX Cloud. Easily train models with H100 GPUs on NVIDIA DGX Cloud for faster, scalable AI development

The era of prompts is over, and AI is moving toward context-aware, intuitive systems. Discover what’s replacing prompts and how the future of AI interfaces is being redefined
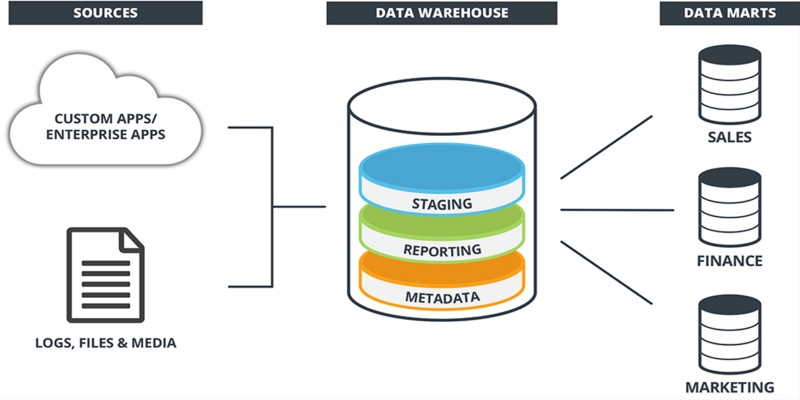
Learn what a data warehouse is, its key components like ETL and schema designs, and how it helps businesses organize large volumes of data for fast, reliable analysis and decision-making

Snowflake's acquisition of Neeva boosts enterprise AI with secure generative AI platforms and advanced data interaction tools

Wondering whether a data lake or data warehouse fits your needs? This guide explains the differences, benefits, and best use cases to help you pick the right data storage solution

Discover the exact AI tools and strategies to build a faceless YouTube channel that earns $10K/month.

How does an AI assistant move from novelty to necessity? OpenAI’s latest ChatGPT update integrates directly with Microsoft 365 and Google Workspace—reshaping how real work happens across teams

Explore the different Python exit commands including quit(), exit(), sys.exit(), and os._exit(), and learn when to use each method to terminate your program effectively

IBM showcased its agentic AI at RSAC 2025, introducing a new approach to autonomous security operations. Learn how this technology enables faster response and smarter defense

How Edge AI is reshaping how devices make real-time decisions by processing data locally. Learn how this shift improves privacy, speed, and reliability across industries