Advertisement
Machine learning models are built to make predictions, but how well those predictions hold up outside the training data depends on their ability to generalize. Some models perform impressively on familiar examples but fail when tested on new, unseen data. Others can handle unfamiliar situations more effectively by focusing on patterns rather than details.
The contrast between generalization and non-generalization is a key challenge in machine learning. Knowing what these terms mean, why they occur, and how to address them can help build systems that perform more reliably beyond controlled environments.
Generalization is a model’s ability to make accurate predictions on data it hasn’t seen before. Instead of memorizing individual examples, a well-generalized model learns underlying patterns. For instance, a model trained to identify cats should still recognize a cat in an unfamiliar photo, even if the background or lighting is different. Generalization is the ultimate aim—training models that perform well in real-world scenarios.
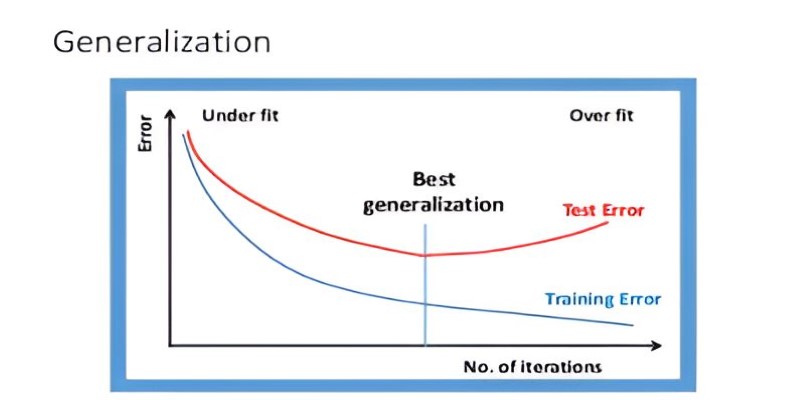
The degree to which a model generalizes depends on training quality, data variety, and model complexity. A model that’s too simple may miss important patterns, known as underfitting. Conversely, a model that’s too complex may memorize noise and irrelevant details in the training data, a problem called overfitting. Overfitted models fail to generalize because they latch onto quirks in the training set rather than genuine relationships.
Balancing simplicity and complexity helps build models that generalize well. Techniques like regularization, cross-validation, and gathering diverse data support this. For example, training on images of cats in a wide range of environments teaches the model to identify a cat regardless of context. Such diversity ensures it learns what actually defines a cat instead of learning to recognize only specific scenarios.
Non-generalization occurs when a model cannot apply what it has learned to new data. This is most commonly due to overfitting or insufficient, biased data. Overfitting happens when a model becomes overly attuned to the specific examples in the training set. If all training photos of cats are taken indoors, the model may associate indoor settings with cats and fail to recognize outdoor images.
Poor generalization can also stem from limited or skewed datasets. A spam detector trained only on one language is unlikely to perform well on messages written in another. Data leakage, where information from the test set inadvertently influences training, can also give a false sense of accuracy while hurting performance on real-world data.
Model structure matters as well. Complex models with many parameters tend to overfit when trained on small datasets. On the other end, very simple models often underfit, missing important patterns and performing poorly on both training and test data. Testing models on separate validation datasets during training is a standard way to detect these issues and adjust before deployment.
Improving generalization is about finding the right balance between model complexity and the richness of the training data. The more diverse and representative the training data, the more likely the model will learn patterns that are actually useful. Data augmentation, which creates synthetic variations of the existing data, can help when the real data is limited. For example, flipping, rotating, or slightly altering images in a training set can help an image classifier generalize better.

Another strategy is regularization. Techniques like dropout or adding penalties for large weights discourage the model from relying too heavily on any single feature, which helps prevent overfitting. Cross-validation is another common method, where the training data is divided into several parts and the model is tested on each part in turn to make sure it performs consistently. These techniques force the model to learn more general patterns rather than memorize specifics.
Selecting the right model size is also critical. A model with too many parameters relative to the amount of training data is prone to overfitting, while a model that is too simple may not capture enough detail. Experimenting with different architectures and monitoring their performance on validation data can help find the right balance.
Monitoring and maintaining generalization is not a one-time task. As real-world data changes over time, models can become stale—a phenomenon called concept drift. Retraining models periodically with fresh data helps keep them generalizable.
At its core, generalization is about teaching a model to learn patterns rather than memorize examples. Memorization gives perfect training accuracy but poor performance on unfamiliar data. Learning patterns ensure the model can handle variations and unexpected scenarios.
Finding this balance isn’t straightforward. Excessive regularization or overly simple models lead to underfitting, where even training performance is low. Too much complexity or too little constraint results in overfitting. Carefully tuning the model and monitoring validation performance are necessary to maintain good generalization.
A model’s ability to generalize defines its usefulness. Non-generalization leaves models fragile and unreliable in practice. Detecting warning signs—like high training accuracy paired with low test accuracy—can prompt early adjustments. Aiming for generalization creates models more likely to succeed in varied and unpredictable conditions, which is what makes machine learning meaningful beyond the training environment.
Generalization and non-generalization reflect two ends of a spectrum in how machine learning models behave when faced with new data. A model that generalizes well is more reliable, flexible, and valuable because it can make correct predictions in situations it hasn’t seen before. Non-generalization, often caused by overfitting, poor data, or overly complex models, limits a model’s effectiveness to the training environment. Balancing model complexity, improving data quality, and using proven techniques like regularization and cross-validation can help achieve better generalization. For anyone building machine learning systems, understanding and addressing these issues is a necessary part of creating models that work when it counts most.
Advertisement

Learn how to install, configure, and run Apache Flume to efficiently collect and transfer streaming log data from multiple sources to destinations like HDFS

Discover ten easy ways of using ChatGPT to analyze and summarize complex documents with simple ChatGPT prompts.

How using open-source AI models can give your startup more control, lower costs, and a faster path to innovation—without relying on expensive black-box systems
Nvidia NeMo Guardrails enhances AI chatbot safety by blocking bias, enforcing rules, and building user trust through control

Can small AI agents understand what they see? Discover how adding vision transforms SmolAgents from scripted tools into adaptable systems that respond to real-world environments

AI-first devices are reshaping how people interact with technology, moving beyond screens and apps to natural, intelligent experiences. Discover how these innovations could one day rival the iPhone by blending convenience, emotion, and AI-driven understanding into everyday life

Nvidia is set to manufacture AI supercomputers in the US for the first time, while Deloitte deepens agentic AI adoption through partnerships with Google Cloud and ServiceNow

How IBM and L’Oréal are leveraging generative AI for cosmetics to develop safer, sustainable, and personalized beauty solutions that meet modern consumer needs

Writer unveils a new AI platform empowering businesses to build and deploy intelligent, task-based agents.

Google risks losing Samsung to Bing if it fails to enhance AI-powered mobile search and deliver smarter, better, faster results
How to use ChatGPT for Google Sheets to automate tasks, generate formulas, and clean data without complex coding or add-ons
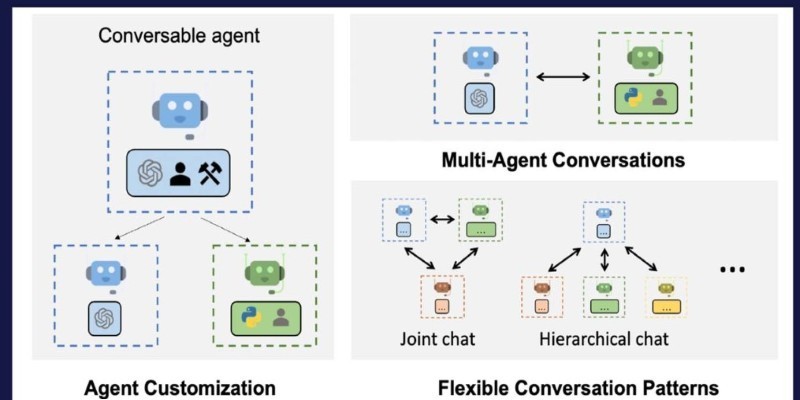
How Building Multi-Agent Framework with AutoGen enables efficient collaboration between AI agents, making complex tasks more manageable and modular