Advertisement
Moving large amounts of data between traditional databases and Hadoop can feel tedious and error-prone without the right tools. Many organizations struggle to make their operational data available for big data analytics, wasting time on custom scripts that often break under load. Apache Sqoop was created to solve this problem with a simple, efficient way to transfer bulk data between relational databases and Hadoop ecosystems.
It eliminates much of the manual work, automating transfers while preserving structure and reliability. For anyone working with both SQL databases and Hadoop, Sqoop offers a practical bridge that makes managing data pipelines far less painful.
Apache Sqoop makes it much easier to move large volumes of data between relational databases and Hadoop. It’s an open-source tool built for importing data from databases like MySQL, Oracle, or PostgreSQL into Hadoop’s Distributed File System (HDFS), Hive, or HBase — and exporting it back when needed. The name itself, short for “SQL-to-Hadoop,” says it all.

Before Sqoop, teams often had to write clunky custom scripts or rely on generic tools that were slow and prone to errors. Sqoop changes that by providing a simple command-line utility that automatically creates and runs efficient MapReduce jobs behind the scenes. It's become a reliable part of data pipelines where structured data is pulled into Hadoop for analysis and then returned to databases after processing, without unnecessary complexity.
Apache Sqoop stands out for a set of features that make it practical for large-scale data movement. At its core, it is designed for high efficiency. Sqoop uses parallel processing by launching multiple MapReduce tasks to handle chunks of data at the same time, which makes importing and exporting much faster than serial approaches.
It also has a simple yet flexible interface. Users can interact with Sqoop through straightforward command-line commands, specifying connection parameters, table names, and target directories or tables. Advanced options allow fine-tuning, such as selecting only specific columns or rows, specifying delimiters, or controlling the number of parallel tasks.
Another notable feature is its tight integration with the Hadoop ecosystem. Sqoop supports not only HDFS but also formats like Avro and SequenceFiles. It can directly populate Hive tables for analysis or write into HBase for low-latency access. It preserves the schema of relational databases when importing, mapping SQL data types to Hadoop-compatible types.
Security and fault tolerance are baked in as well. Sqoop supports Kerberos authentication, so it works in secure Hadoop clusters, and it can resume operations gracefully if tasks fail. Combined, these features make it reliable enough for production workloads without much manual intervention.
The architecture of Apache Sqoop is straightforward yet effective, designed to leverage Hadoop’s distributed capabilities. It doesn’t run as a long-running service but instead acts as a client application that generates MapReduce jobs. When a user runs a Sqoop command, it parses the command-line arguments to determine the operation — import or export — and then uses metadata from the database to prepare the job.

For an import job, Sqoop connects to the relational database using JDBC to retrieve the schema and partition information. Based on the number of parallel tasks specified, it divides the input data into splits, each handled by a separate mapper. These mappers run on different nodes in the Hadoop cluster, each fetching a portion of the data directly from the database and writing it into HDFS or Hive.
The export process works in a similar way but in reverse. Sqoop reads data from HDFS and launches mappers that write their respective chunks into the target database using prepared statements over JDBC. There is no reducer phase in these jobs, since the work is embarrassingly parallel.
Since it relies on Hadoop’s fault-tolerance, if any mapper task fails, Hadoop can re-run it without affecting the rest of the job. This design keeps the core of Sqoop simple while making full use of Hadoop’s distributed processing, making it both scalable and reliable.
In a real-world scenario, a data engineer might use Sqoop as part of a daily workflow to sync operational databases with a Hadoop data warehouse. A typical import job begins with defining the connection to the database, specifying the table to import, and pointing to a target directory or Hive table. For example, a command might specify importing just certain columns or filtering rows with a SQL WHERE clause, which Sqoop passes through to the database.
During the job, Sqoop automatically generates Java classes to represent the rows of the table being imported. Each mapper task runs these classes to fetch rows in parallel and write them into Hadoop. Users can control the file format, choosing between plain text, Avro, or SequenceFile formats depending on downstream needs.
When exporting data, a similar approach applies. Sqoop reads records from HDFS, maps them into SQL statements, and writes them into the database. It handles batching and transactions efficiently to ensure data integrity. Users can choose between inserting new rows or updating existing ones, and they can configure batch size and commit frequency to balance performance with reliability.
Sqoop is often scheduled to run as part of larger workflows using tools like Apache Oozie, making it an integral part of enterprise data pipelines. Its ability to move data in both directions — into Hadoop for analysis and back to databases for reporting — is one of its biggest strengths. This two-way capability allows organizations to keep their analytics and operational systems in sync without complex development effort.
Apache Sqoop has become a trusted utility for bridging the gap between traditional databases and Hadoop. Its simplicity hides a powerful, distributed mechanism that can handle large volumes of data reliably and quickly. The ability to integrate with key components like HDFS, Hive, and HBase while respecting the structure of relational data makes it a valuable tool in many data architectures. For teams managing data workflows between transactional and analytical systems, Sqoop provides a practical solution that reduces manual effort and ensures data stays consistent across environments. Its role in modern data pipelines highlights how thoughtful, specialized tools can make managing big data ecosystems more approachable.
Advertisement

At CES 2025, Hyundai and Nvidia unveiled their AI Future Mobility Program, aiming to transform transportation with smarter, safer, and more adaptive vehicle technologies powered by advanced AI computing

How IBM and L’Oréal are leveraging generative AI for cosmetics to develop safer, sustainable, and personalized beauty solutions that meet modern consumer needs

Is the future of U.S. manufacturing shifting back home? Siemens thinks so. With a $190M hub in Fort Worth, the company is betting big on AI, automation, and domestic production

Writer unveils a new AI platform empowering businesses to build and deploy intelligent, task-based agents.

How MPT-7B and MPT-30B from MosaicML are pushing the boundaries of open-source LLM technology. Learn about their architecture, use cases, and why these models are setting a new standard for accessible AI
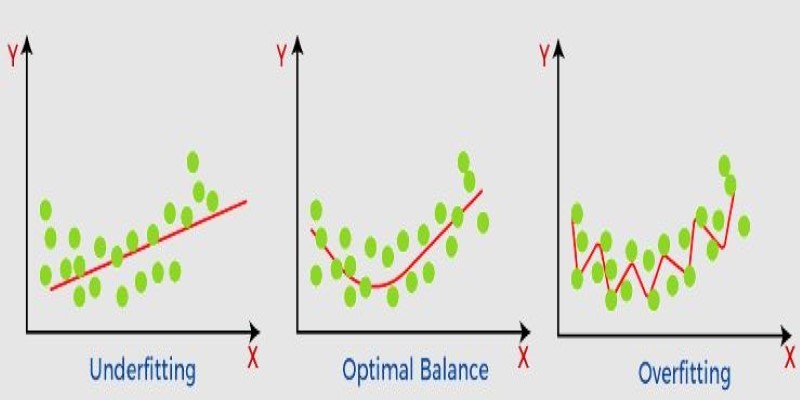
What non-generalization and generalization mean in machine learning models, why they happen, and how to improve model generalization for reliable predictions

Discover execution speed differences between C and Rust. Learn benchmarks, optimizations, and practical trade-offs for developers

Know how AI transforms Cybersecurity with fast threat detection, reduced errors, and the risks of high costs and overdependence

Discover ten easy ways of using ChatGPT to analyze and summarize complex documents with simple ChatGPT prompts.

How using open-source AI models can give your startup more control, lower costs, and a faster path to innovation—without relying on expensive black-box systems

How the Model-Connection Platform (MCP) helps organizations connect LLMs to internal data efficiently and securely. Learn how MCP improves access, accuracy, and productivity without changing your existing systems
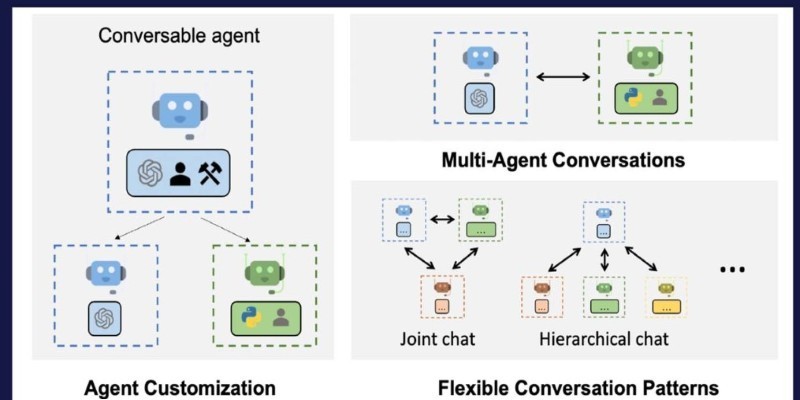
How Building Multi-Agent Framework with AutoGen enables efficient collaboration between AI agents, making complex tasks more manageable and modular