Advertisement
Large Language Models (LLMs) have changed the way we interact with code. They help with writing, understanding, translating, and even fixing code across languages. But building one from scratch for this purpose takes more than just pointing a model at a data dump and hoping it learns. It’s a step-by-step process that needs thought, the right ingredients, and an understanding of how code works both as syntax and logic. If you’re curious about how it all comes together, let’s look at how LLMs built for code actually come to life.
Before you start anything technical, figure out what you want your model to do. This sounds obvious, but it shapes every other decision. Are you building a model that writes Python scripts? Or something that reads C++ and suggests bug fixes? Maybe you want it to convert JavaScript to TypeScript. Each use case has its own demands in terms of size, data, and evaluation.
Once that’s clear, pick a programming language or set of languages. Some go for single-language expertise (like Codex and Python), while others aim for a broader understanding of multiple languages. Going narrow can lead to better results with fewer resources, but going wide opens up more use cases.
Then ask: How big does your model need to be? A 100M parameter model will behave very differently from a 6 Bone. The larger it is, the more compute and data you'll need, so match this to your resources.
This part is more work than most expect. Code isn’t like natural language—it needs to compile, follow rules, and solve problems. So, the quality of the dataset matters a lot more.
Start with open-source repositories. GitHub is a common choice, but you have to be careful. Many files are incomplete, poorly written, or just not helpful for training. Collect files with working examples, full functions, or documented scripts. Stack Overflow dumps, coding forums, and public course materials are useful, too, but treat them with the same scrutiny.
Once you gather data, cleaning it becomes the next hurdle. This means:
For code-specific models, you can even go further and include metadata like commit messages, docstrings, or problem descriptions. These act as the “prompt” side of the input and make models better at in-context use.
Some add unit tests or problem-and-solution pairs. Others tag code snippets with language identifiers, which help the model distinguish Python from Java, even if they look similar.

Tokenization for code is not like tokenization for plain text. You can’t just split on spaces and punctuation. You’ll end up breaking logical parts of the code, and the model won’t learn anything meaningful.
The usual approach is to train a byte-pair encoding (BPE) tokenizer or use something like SentencePiece. These let you break down the code into sub-tokens that preserve meaning. For example, parse_input might get split into parse and _input, which keeps the structure of identifiers intact.
Some prefer a custom tokenizer based on the programming language itself—like a lexer-style tokenizer. This way, you split code into tokens, such as keywords, variables, literals, and operators, making it more readable for the model.
No matter what route you pick, keep one thing in mind: the tokenizer must strike a balance between vocabulary size and sequence length. Too large, and you run into memory issues. It is too small, and your model has to guess too much context.
Now comes the actual training. At this point, you’ve got cleaned, tokenized data and a clear goal. But how do you train a model that can understand and write code?
Here’s how it’s done:

Most coding LLMs use a transformer-based decoder-only architecture. This is similar to GPT-style models. If you're training from scratch, use something standard like GPT-2, GPT-Neo, or GPT-J as your base. These are open-source, well-documented, and flexible.
If you want to finetune an existing model instead, something like CodeGen, StarCoder, or Mistral might be better. These have been trained on code already and can be adapted with less data.
You’ll need a distributed setup with multiple GPUs or TPUs. Code models, especially larger ones, take time and memory to train. Use libraries like DeepSpeed, Hugging Face Accelerate, or FSDP to handle parallelization. Keep an eye on checkpointing and memory limits—code tends to be long, so sequence lengths might be higher than for text models.
Use the standard causal language modeling objective: predict the next token given the previous ones. That's enough to make the model learn syntax, patterns, and logic flow. You don't need fancy objectives if your data is good.
For better results, use curriculum learning: start with simple examples, then gradually add more complex, multi-file projects or mixed-language inputs. This helps the model form a base understanding before diving into edge cases.
Hold out some part of the dataset to act as validation. Use code-specific metrics like:
Don’t just trust loss going down. Run code generated by the model. Does it compile? Does it solve the original problem? These checks matter more than just accuracy or perplexity.
Building an LLM for code isn’t a black box—it’s a process that needs the right target, clean data, and careful design. If you put in the effort upfront—cleaning, curating, and training with a clear purpose—you’ll end up with a model that understands how humans write code, not just how it looks. And that’s where the real value lies.
Advertisement

Discover the best Artificial Intelligence movies that explore emotion, identity, and the blurred line between humans and machines. From “Her” to “The Matrix,” these classics show how AI in cinema has shaped the way we think about technology and humanity

The era of prompts is over, and AI is moving toward context-aware, intuitive systems. Discover what’s replacing prompts and how the future of AI interfaces is being redefined
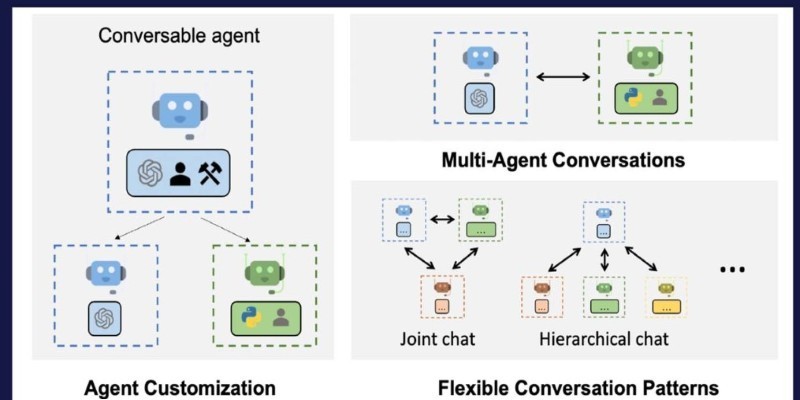
How Building Multi-Agent Framework with AutoGen enables efficient collaboration between AI agents, making complex tasks more manageable and modular

Snowflake's acquisition of Neeva boosts enterprise AI with secure generative AI platforms and advanced data interaction tools
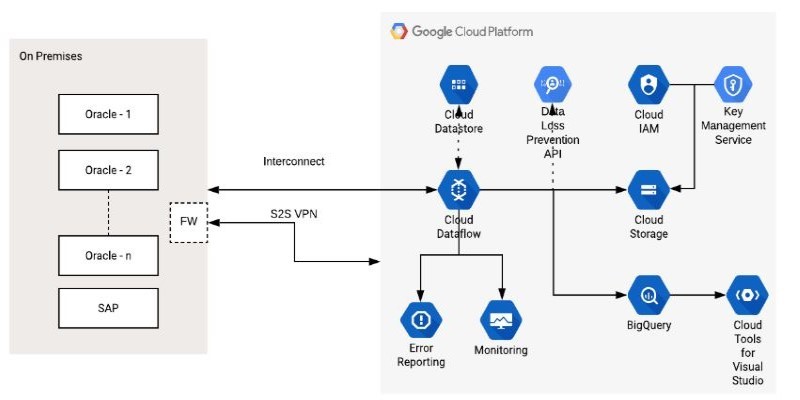
How the Google Cloud Dataflow Model helps you build unified, scalable data pipelines for streaming and batch processing. Learn its features, benefits, and connection with Apache Beam

Accelerate AI with AWS GenAI tools offering scalable image creation and model training using Bedrock and SageMaker features

Ready to make computers see like humans? Learn how to get started with OpenCV—install it, process images, apply filters, and build a real foundation in computer vision with just Python

Discover execution speed differences between C and Rust. Learn benchmarks, optimizations, and practical trade-offs for developers

How AI is changing the future of work, who controls its growth, and the hidden role venture capital plays in shaping its impact across industries

Wondering whether a data lake or data warehouse fits your needs? This guide explains the differences, benefits, and best use cases to help you pick the right data storage solution
How does Docmatix reshape document understanding for machines? See why this real-world dataset with diverse layouts, OCR, and multilingual data is now essential for building DocVQA systems

How a machine learning algorithm uses wearable technology data to predict mood changes, offering early insights into emotional well-being and mental health trends