Advertisement
When trying to teach a machine how to understand documents the way we do, you quickly realize it’s not just about reading text. There’s layout, font styles, logos, tables, stamps, and a ton of formatting quirks that humans process without thinking. Machines don’t do that automatically. That’s where datasets like Docmatix come into play.
Docmatix isn’t just big. It’s built in a way that reflects how real-world documents work — invoices, forms, memos, IDs, manuals, and more. This makes it especially useful for training systems that need to answer questions by “looking” at both the text and how that text is arranged. Let’s break down what makes Docmatix stand out in the world of Document Visual Question Answering, or DocVQA.
At its core, Docmatix is a dataset designed to help machines understand and answer questions about documents by analyzing both their content and layout. However, this isn't just about assembling scanned files and adding a few prompts. It's a curated, diverse, and structured dataset comprising several thousand documents that cover dozens of document types.

Most older datasets either focus on the text part of documents or layout understanding, but not both in a balanced way. Docmatix brings both into play with clear intent — training systems that can handle the messiness of real documents. Not just clean, perfect PDFs. We're talking about wrinkled, scanned, handwritten, cropped, and annotated documents — the kind that appear in actual offices and databases.
Each document in the dataset is paired with multiple questions that refer to either the entire page, a specific region, or something that depends on both reading and interpreting layout. This makes the problem closer to how a human would approach it: read, look around, consider the context, and then answer.
The design of the Docmatix dataset makes it very practical. It includes:
Over 300,000 QA pairs: These are human-generated questions and answers based on document images.
Multiple document types: Forms, tax records, academic transcripts, user manuals, receipts, and more.
Visual reasoning elements: Many questions require understanding tables, layout zones, or text blocks placed in unique spots.
OCR-aligned: Each image is paired with OCR (Optical Character Recognition) output so models can compare raw images with extracted text.
Bounding boxes: These highlight the exact location of relevant text snippets or fields.
Multi-lingual support: There’s a chunk of documents in languages other than English, which gives it more reach than most datasets.
By including OCR output and visual features together, Docmatix allows models to align the semantic meaning of the words with where and how they appear on the page. And that’s exactly what makes it so useful.
In traditional VQA (Visual Question Answering), models mostly work with natural images — like pictures of street signs, animals, or objects. But DocVQA is more technical. It deals with structured and semi-structured data that need both visual and textual reasoning. For example:
Now imagine training a model to spot that, especially when every invoice looks slightly different.
This is where Docmatix becomes handy. It doesn’t just offer variety; it offers functional diversity — invoices with rotated text, partially filled forms, old-style reports, annotated images with handwriting, and blurred stamps. That kind of noise is what models must learn to handle.
Models trained on Docmatix learn not just to read but to locate and infer. They don't need everything to be obvious or clean. That's a big step toward making DocVQA systems more reliable.
If you’re planning to train a Document VQA system using Docmatix, here's how you can structure the process:

Start with document images from the dataset. You’ll run OCR on these images to extract text. Most models use engines like Tesseract or Google’s OCR system for this.
You’ll get:
Some entries in Docmatix already have OCR applied, which can speed up experimentation.
After OCR, it's time to understand the structure. This includes:
Docmatix provides layout annotations, which can be used to train models that do layout-aware parsing.
Feed the model with a combination of:
You can train using transformer-based models like LayoutLMv3 or Donut, which are designed to handle multi-modal input.
Training here is more than just matching words — it’s learning spatial awareness. For instance, understanding that a question asking “What is the total?” likely refers to the bottom right of a receipt or an invoice.
Docmatix comes with suggested evaluation benchmarks:
These help you track whether your model is actually learning to reason visually or just guessing based on keywords.
Docmatix isn't just another dataset. It presents a clear and realistic challenge to the field of Document Visual Question Answering by combining the challenging aspects of OCR, layout interpretation, and question answering into a single package. Models trained on it learn to function in real-world document scenarios, not lab-perfect samples.
If you're building a DocVQA system that needs to work with messy, diverse, and everyday documents, Docmatix provides the kind of training data that forces your model to become smarter. Not just better at reading but better at understanding where to look and how to connect pieces of information that aren't always in obvious places. That's the edge it offers.
Advertisement

How serverless GPU inference is transforming the way Hugging Face users deploy AI models. Learn how on-demand, GPU-powered APIs simplify scaling and cut down infrastructure costs

Writer unveils a new AI platform empowering businesses to build and deploy intelligent, task-based agents.
Speed up your deep learning projects with NVIDIA DGX Cloud. Easily train models with H100 GPUs on NVIDIA DGX Cloud for faster, scalable AI development

Can a small language model actually be useful? Discover how SmolLM runs fast, works offline, and keeps responses sharp—making it the go-to choice for developers who want simplicity and speed without losing quality

IBM showcased its agentic AI at RSAC 2025, introducing a new approach to autonomous security operations. Learn how this technology enables faster response and smarter defense
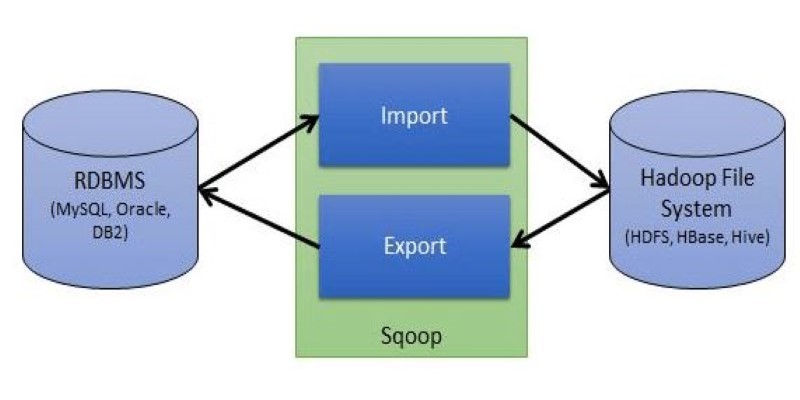
Explore Apache Sqoop, its features, architecture, and operations. Learn how this tool simplifies data transfer between Hadoop and relational databases with speed and reliability

Snowflake's acquisition of Neeva boosts enterprise AI with secure generative AI platforms and advanced data interaction tools

Discover a clear SQL and PL/SQL comparison to understand how these two database languages differ and complement each other. Learn when to use each effectively

How does an AI assistant move from novelty to necessity? OpenAI’s latest ChatGPT update integrates directly with Microsoft 365 and Google Workspace—reshaping how real work happens across teams

Can small AI agents understand what they see? Discover how adding vision transforms SmolAgents from scripted tools into adaptable systems that respond to real-world environments
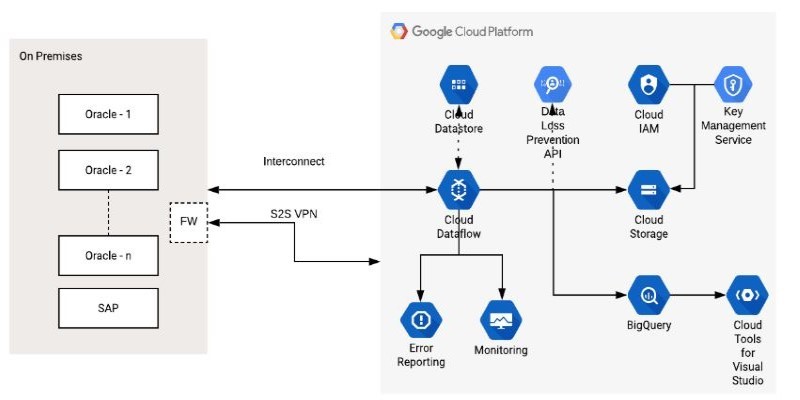
How the Google Cloud Dataflow Model helps you build unified, scalable data pipelines for streaming and batch processing. Learn its features, benefits, and connection with Apache Beam
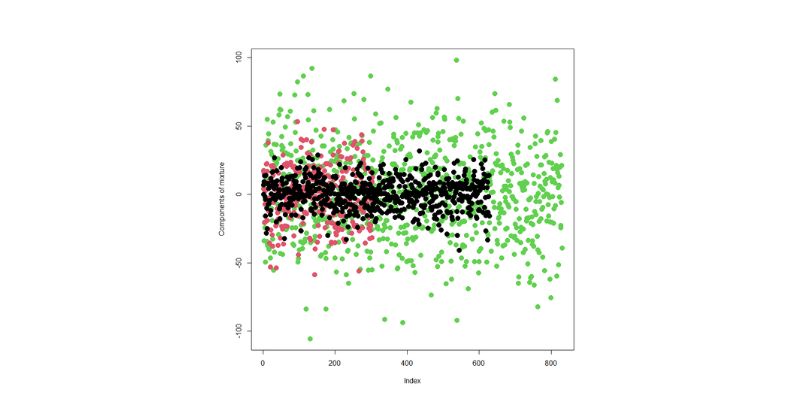
Learn how integrating feature selection into model estimation improves accuracy, reduces noise, and boosts efficiency in ML