Advertisement
Running large language models efficiently isn’t just a cloud-scale problem anymore. Small, powerful models are changing how inference happens at the edge, and one standout in this space is SetFit — a method that trains text classifiers with minimal labelled data. But to make it truly practical for real-world use, speed is key.
That's where Hugging Face Optimum Intel comes in, offering performance-focused tools designed for Intel Xeon processors. When SetFit meets Optimum Intel on Xeon, the result is a much faster, more efficient pipeline that works without cutting accuracy.
SetFit stands for Sentence Transformer Fine-tuning. It’s built around the idea that you can train models using just a few examples per class — a method called few-shot learning. Instead of relying on heavy classification heads and tons of annotated data, SetFit repurposes sentence transformers, which are pre-trained on massive amounts of data and can be easily fine-tuned with contrastive learning. Once fine-tuned, the model uses a simple classifier trained on embeddings, giving you quick, reliable outputs without heavy lifting.
This approach is ideal for use cases like customer support ticket tagging, legal document classification, or any domain where data is limited and training time matters. SetFit skips the usual long training cycles and gets models production-ready with fewer resources. But inference — the actual moment when predictions are made — can still become a bottleneck if not optimized. That's where hardware and software optimization step in.
Optimum Intel is Hugging Face's specialized toolkit aimed at maximizing performance on Intel architecture. It connects the Hugging Face Transformers ecosystem with Intel's low-level inference accelerators, such as Intel Neural Compressor (INC) and OpenVINO. These tools do more than just speed things up — they help models run more efficiently using less memory and compute without affecting results.

When applied to SetFit, Optimum Intel enables inference that’s both faster and lighter. The Xeon platform, often used in data centers and enterprise backends, is well suited to run SetFit inference pipelines — especially when paired with techniques like quantization and dynamic input batching that Optimum Intel supports.
Using these tools, a typical SetFit pipeline on Xeon can cut inference latency significantly. We're talking milliseconds per query, not seconds. The biggest advantage? This doesn't come at the cost of flexibility. The model retains its ability to handle various tasks without needing large reworks or hardware-specific engineering.
Intel Xeon processors aren’t just built for brute compute; they're tuned for real-world application workloads. With large L3 caches, scalable vector extension (AVX-512), and deep integration with memory and I/O systems, they excel in running optimised machine learning tasks, such as SetFit inference, at high throughput.
Thanks to Hugging Face Optimum Intel, models like SetFit can be quantized from FP32 to INT8 with minimal performance loss. Quantization reduces model size and speeds up matrix operations, which are the core of any transformer-based architecture. Xeon processors make great use of this because their instruction sets support these compact data formats natively.
Moreover, Optimum Intel simplifies this entire pipeline. Developers don’t need to be hardware specialists. With a few lines of code, they can export their fine-tuned SetFit model, run INC to calibrate and quantize it and load it back into a runtime optimized for Xeon. This means reduced deployment time, more predictable performance, and a much smaller hardware footprint — perfect for enterprise teams managing multiple inference endpoints.
An added benefit of running SetFit on Xeon is the balance between performance and flexibility. Xeon supports a range of workloads beyond NLP, which makes it a smart pick for companies that want to consolidate their infrastructure. You don’t need separate hardware for vision, tabular data, and text — a well-configured Xeon server can handle them all.
When you move from a research or prototype stage to production, small inefficiencies in inference quickly add up. A few hundred milliseconds per prediction might seem trivial until you’re handling thousands of queries per second. This is where the combination of SetFit, Optimum Intel, and Xeon shows its real value — scaling without a spike in cost or complexity.

For example, in customer-facing applications like search relevance, smart tagging, or live sentiment monitoring, inference speed directly shapes user experience. Using SetFit with Optimum Intel lets developers compress inference time while keeping the model simple and easy to update. Teams can fine-tune the model on new data and re-quantize it within hours, not days, maintaining agility.
Another important area is security and compliance. Running inference on-premises with Xeon-based servers gives enterprises more control over data handling, which is a growing requirement in sectors like healthcare and finance. Pairing this with an efficient model like SetFit keeps infrastructure light without giving up performance.
Even for batch processing — say, labelling millions of documents overnight — optimized SetFit on Xeon finishes faster and uses fewer resources. This lets organizations reduce server time, cut energy costs, improve system throughput, and still meet tight deadlines. The result is a leaner pipeline that can keep up with production demands without scaling hardware vertically.
Bringing SetFit to production is no longer just about having a smart model — it's about how quickly and efficiently it can make predictions across different workloads and environments. Hugging Face Optimum Intel, designed to squeeze the most out of Intel Xeon processors, makes this possible by offering a path to blazing fast inference without complexity. SetFit’s lightweight fine-tuning meets Optimum Intel’s performance tools in a setup that’s both fast and flexible. Whether you're building for real-time applications or handling massive offline tasks, this combination delivers low-latency results with minimal trade-offs. And it does all of this on hardware that’s already trusted across enterprise environments.
Advertisement
An AI startup has raised $1.6 million in seed funding to expand its practical automation tools for businesses. Learn how this AI startup plans to make artificial intelligence simpler and more accessible

At CES 2025, Hyundai and Nvidia unveiled their AI Future Mobility Program, aiming to transform transportation with smarter, safer, and more adaptive vehicle technologies powered by advanced AI computing

How to classify images from the CIFAR-10 dataset using a CNN. This clear guide explains the process, from building and training the model to improving and deploying it effectively

Sam Altman returns as OpenAI CEO amid calls for ethical reforms, stronger governance, restored trust in leadership, and more

How LLMs and BERT handle language tasks like sentiment analysis, content generation, and question answering. Learn where each model fits in modern language model applications

Learn the difference between SSH and Telnet in cyber security. This article explains how these two protocols work, their security implications, and why SSH is preferred today

How a machine learning algorithm uses wearable technology data to predict mood changes, offering early insights into emotional well-being and mental health trends

Discover ten easy ways of using ChatGPT to analyze and summarize complex documents with simple ChatGPT prompts.

How MPT-7B and MPT-30B from MosaicML are pushing the boundaries of open-source LLM technology. Learn about their architecture, use cases, and why these models are setting a new standard for accessible AI

How IonQ advances AI capabilities with quantum-enhanced applications, combining stable trapped-ion technology and machine learning to solve complex real-world problems efficiently

How does an AI assistant move from novelty to necessity? OpenAI’s latest ChatGPT update integrates directly with Microsoft 365 and Google Workspace—reshaping how real work happens across teams
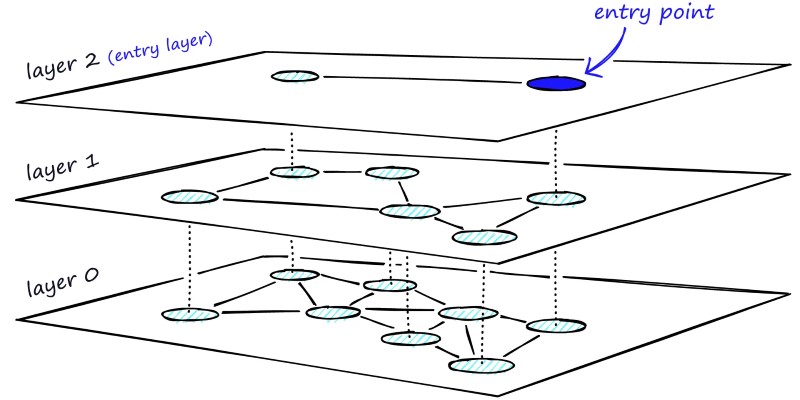
Learn how HNSW enables fast and accurate approximate nearest neighbor search using a layered graph structure. Ideal for recommendation systems, vector search, and high-dimensional datasets