Advertisement
What happens after an AI model is trained? Most of the conversation around artificial intelligence focuses on training large language models—billions of parameters, mountains of data, and expensive GPUs. But that's only part of the picture. The other side, often overlooked but just as important, is inference. It's the moment when a model generates output based on a prompt.
In real-world applications—whether it's answering a question, finishing a sentence, or writing a paragraph—speed, cost, and quality during inference can make or break the product. Benchmarking text generation inference helps us see where models succeed, where they slow down, and how they handle load under pressure.
Text generation inference refers to the process of generating text using a pre-trained language model. You feed it an input prompt, and it returns a sequence of words as output. While this might seem simple on the surface, the actual computation involved is quite dense. The model has to predict the next token in a sequence, often using a decoder-only architecture like a transformer. It does this again and again, token by token until a stopping condition is reached.
There are multiple factors influencing inference behaviour. Model size is one of them—larger models can generate more nuanced responses but require more memory and computation. Hardware also plays a role; some models run better on GPUs, and others can be optimized for CPUs or even custom chips like TPUs. On top of that, decoding strategies—such as greedy decoding, beam search, or nucleus sampling—impact how fast and coherent the output is.
Benchmarking helps quantify how all these factors interact. It tells us, for example, whether a model's response time gets slower with longer inputs or how it performs when handling multiple requests simultaneously. This kind of evaluation isn't just for researchers—product teams, developers, and infrastructure engineers rely on these benchmarks to make decisions about deployment and user experience.
When benchmarking text generation inference, three core metrics tend to come up: latency, throughput, and output quality.

Latency measures the time it takes for a model to respond to a prompt. For user-facing applications, such as chatbots, low latency is crucial. No one wants to wait five seconds for a response. Even in non-interactive systems, high latency can limit scalability and drive up compute costs.
Throughput refers to the number of inference requests a system can handle per second. If you're running a model behind an API, high throughput means you can serve more users at the same time. This is especially relevant in batch processing, customer service automation, and large-scale content generation.
Output quality, meanwhile, is harder to quantify. It involves fluency, relevance, and factual accuracy. While some benchmarks use human ratings or metrics like BLEU or ROUGE, those don't always align with how people perceive quality. A high-quality output should sound natural, stay on topic, and meet the user's intent. Testing this at scale is challenging but necessary.
Trade-offs are inevitable. A model optimized for speed might lose some coherence. One focused on accuracy might sacrifice response time. Good benchmarking helps identify these trade-offs clearly, allowing teams to pick the right model and configuration for their specific use case.
In practice, benchmarking inference is messier than it seems. First, the results vary depending on context. A model might perform well on short prompts but struggle with long, complex ones. Or it might do fine with batch processing but break under real-time, concurrent user loads.
Hardware availability and cost are another issue. Many organizations don't have access to high-end GPUs or custom AI accelerators. That means benchmark results need to be tested on a range of environments—consumer-grade GPUs, cloud-based machines, and even edge devices—to understand practical limitations.
Then, there's software overhead. The inference framework, memory management, and parallelization strategy all influence how fast a model runs. Even something as basic as using a different tokenizer can affect latency. So, benchmark results are only useful when the setup is clearly described and consistent. Otherwise, it's hard to reproduce or compare them.
One more layer of complexity is decoding. Sampling parameters—like temperature, top-k, or top-p—change the output unpredictably. Two models might have the same architecture, but different decoding settings can lead to dramatically different results. For fair benchmarking, those settings need to be standardized or at least transparent.
And finally, models evolve quickly. A benchmark from six months ago might already be outdated as new architectures like Mixture of Experts or quantized transformers become more common, benchmarking needs to keep up with what's actually being used in production.
To make benchmarking more useful, it needs to be purpose-driven. There’s no single best model for every situation. A chatbot on a mobile app has different needs than a document summarization tool on a server. Benchmarks should reflect real usage patterns, including input length, prompt complexity, and expected response time.

Testing under load is also important. How does the model handle 100 requests per second? What if multiple threads hit the API at once? Load tests show how systems hold up under stress.
Evaluating output quality matters, too. That means combining human feedback with automated scoring. Speed and scale mean little if responses are off-topic or incoherent. Some teams use hybrid benchmarks that track both latency and output quality.
Testing across hardware types helps, especially when budgets are limited. A model might run fast on a GPU but struggle on CPUs or edge chips. Cross-platform testing gives a more realistic view of performance.
Finally, sharing benchmark results—along with setup details—benefits everyone. Open, repeatable benchmarks enable developers and teams to build faster, more effective models.
Benchmarking text generation inference isn't just about performance stats—it shapes how real users experience AI. Speed, quality, and scalability all matter, but they vary depending on the task and environment. Purpose-driven benchmarks, tested under realistic conditions and shared transparently, lead to better outcomes for everyone. As models become more widely used, solid benchmarking helps teams deploy them effectively, keeping both technical limits and user needs in balance.
Advertisement

Learn how to install, configure, and run Apache Flume to efficiently collect and transfer streaming log data from multiple sources to destinations like HDFS

Watsonx AI bots help IBM Consulting deliver faster, scalable, and ethical generative AI solutions across global client projects

How serverless GPU inference is transforming the way Hugging Face users deploy AI models. Learn how on-demand, GPU-powered APIs simplify scaling and cut down infrastructure costs
How to use ChatGPT for Google Sheets to automate tasks, generate formulas, and clean data without complex coding or add-ons
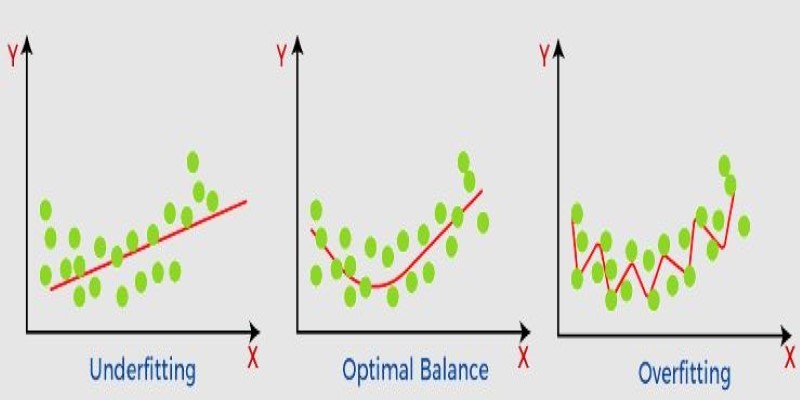
What non-generalization and generalization mean in machine learning models, why they happen, and how to improve model generalization for reliable predictions

Discover a clear SQL and PL/SQL comparison to understand how these two database languages differ and complement each other. Learn when to use each effectively

How the Model-Connection Platform (MCP) helps organizations connect LLMs to internal data efficiently and securely. Learn how MCP improves access, accuracy, and productivity without changing your existing systems

Discover the best Artificial Intelligence movies that explore emotion, identity, and the blurred line between humans and machines. From “Her” to “The Matrix,” these classics show how AI in cinema has shaped the way we think about technology and humanity

How LLMs and BERT handle language tasks like sentiment analysis, content generation, and question answering. Learn where each model fits in modern language model applications

Writer unveils a new AI platform empowering businesses to build and deploy intelligent, task-based agents.

The era of prompts is over, and AI is moving toward context-aware, intuitive systems. Discover what’s replacing prompts and how the future of AI interfaces is being redefined

Get full control over Python outputs with this clear guide to mastering f-strings in Python. Learn formatting tricks, expressions, alignment, and more—all made simple