Advertisement
Deciding between a data lake or a data warehouse often feels less like picking a tool and more like choosing a philosophy. Both promise to help you make sense of your data, yet they approach the challenge from very different angles. A data lake offers openness and flexibility, letting you store everything without judgment.
A data warehouse gives you order and reliability, turning raw facts into clear answers. The real question isn't which is better in general, but which works better for how you use information. Understanding their differences helps you invest wisely without locking yourself into the wrong data storage solution.
A data lake is designed to store all kinds of data—structured, semi-structured, and unstructured—in its raw form. This means you can upload files, logs, images, and even sensor data without needing to organize it first. It's like a vast reservoir where everything can be kept until you decide how to use it. Data lakes are built on low-cost storage systems, often in the cloud, which makes them relatively affordable to scale. They are well-suited for scenarios where you collect large volumes of diverse data but don't yet know all the questions you want to answer.

A data warehouse, by contrast, focuses on structured data. Before storing anything, you organize and clean it, ensuring it fits into defined tables and schemas. This is ideal for standardized reporting, dashboards, and decision-making, where accuracy and speed are more important than flexibility. Warehouses are often more expensive to maintain because they involve ongoing transformation of incoming data. However, the payoff is fast, reliable performance, and consistent results.
In short, a data lake keeps everything as-is for later exploration, while a data warehouse delivers curated, ready-to-use information for day-to-day business needs.
One of the main differences lies in how each approach fits specific use cases. If your work involves advanced analytics, machine learning, or working with audio, video, or social media feeds, a data lake is a better fit. It doesn't force you to define a structure upfront, which is helpful when your data comes from varied sources or when you're experimenting with what insights are possible.
On the other hand, if your priority is clear reporting—such as monthly sales trends, inventory tracking, or customer retention metrics—a data warehouse is more appropriate. Its structure ensures that your data is clean, reliable, and easy to access. Teams that rely on traditional business intelligence tools often prefer warehouses because they integrate seamlessly with those tools and produce consistent, predictable reports.
Performance is another area where the two differ. Warehouses are optimized for queries and tend to respond quickly, even with complex calculations. Data lakes, because of their unstructured nature, can be slower when it comes to analysis. You often need to clean and process the data on the fly, which takes time and technical skill.
Cost considerations also play a role. Storing raw data in a data lake is cheaper because you're not paying for processing or a strict structure upfront. But analyzing that data later may require additional computing power, which can offset the initial savings. A warehouse, while more costly per gigabyte, can reduce analysis costs because the data is already organized and optimized for queries.
Choosing a data storage solution often involves balancing flexibility, cost, and readiness. Neither a data lake nor a data warehouse is designed to solve every problem alone. Many organizations now use both as part of a layered strategy. A data lake acts as the raw collection layer, where everything is stored without immediate structure, and the data warehouse serves as the refined, operational layer that powers reporting and dashboards.

This approach requires clear planning about which data lives where and how it flows between systems. Without discipline, a data lake can become cluttered and hard to manage, while a warehouse can become costly if overused for data that doesn’t need structuring yet. Deciding which data storage solution to emphasize should come from understanding your business questions and technical capabilities, not from chasing trends.
Choosing between a data lake and a data warehouse depends entirely on your priorities and the skills available in your team. If you’re in an industry where experimentation and discovery are constant—like research, technology development, or media—a data lake can give you the flexibility you need. It lets you keep all your data without worrying about what to do with it right away. But it does come with a trade-off: you’ll need people who can clean, process, and make sense of that data when the time comes.
If your business is more focused on efficiency, clear metrics, and regular reporting, a data warehouse is usually better. It’s particularly suited for finance, operations, and retail, where accuracy and repeatability matter more than flexibility. You can trust that your dashboards will always show reliable figures, which helps with decision-making at all levels.
Some organizations even use both together—a data lake as a broad collection point and a data warehouse as the polished layer for analytics. This hybrid approach works well when you have varied needs but requires careful planning and maintenance to avoid duplication or confusion.
Both data lakes and data warehouses have a clear place in modern data management, and neither is universally better than the other. A data lake is more flexible and affordable upfront, especially when dealing with messy, varied data types. A data warehouse provides structure and speed for clear, consistent insights. The best choice depends on your goals, the type of data you handle, and the expertise you have to manage it. Rather than focusing on which is better overall, think about which aligns with how you use data today and what you plan to achieve tomorrow.
Advertisement

Discover the latest machine learning salary trends shaping 2025. Explore how experience, location, and industry impact earnings, and learn why AI careers continue to offer strong growth and global opportunities for skilled professionals
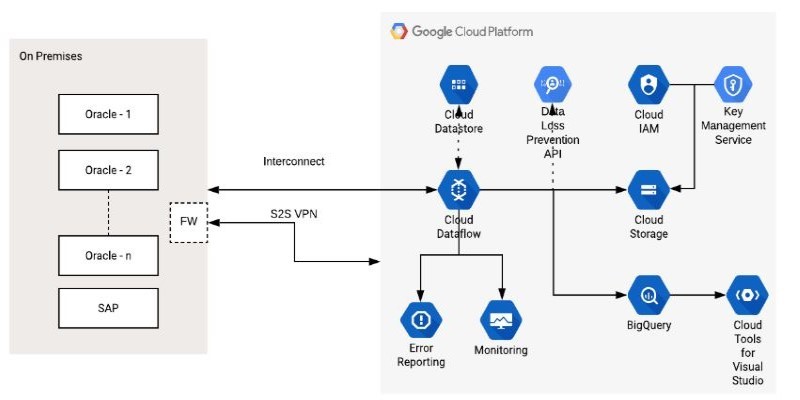
How the Google Cloud Dataflow Model helps you build unified, scalable data pipelines for streaming and batch processing. Learn its features, benefits, and connection with Apache Beam

Curious how LLMs learn to write and understand code? From setting a goal to cleaning datasets and training with intent, here’s how coding models actually come together

Know how AI transforms Cybersecurity with fast threat detection, reduced errors, and the risks of high costs and overdependence

Discover ten easy ways of using ChatGPT to analyze and summarize complex documents with simple ChatGPT prompts.

How a machine learning algorithm uses wearable technology data to predict mood changes, offering early insights into emotional well-being and mental health trends
How IBM expands AI features for the 2025 Masters Tournament, delivering smarter highlights, personalized fan interaction, and improved accessibility for a more engaging experience

Learn the top 5 AI change management strategies and practical checklists to guide your enterprise transformation in 2025.
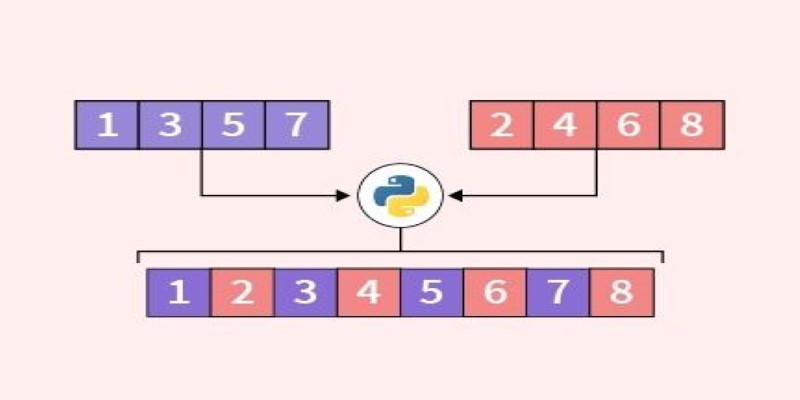
Looking for the best way to merge two lists in Python? This guide walks through ten practical methods with simple examples. Whether you're scripting or building something big, learn how to combine lists in Python without extra complexity

At CES 2025, Hyundai and Nvidia unveiled their AI Future Mobility Program, aiming to transform transportation with smarter, safer, and more adaptive vehicle technologies powered by advanced AI computing

How Edge AI is reshaping how devices make real-time decisions by processing data locally. Learn how this shift improves privacy, speed, and reliability across industries

IBM showcased its agentic AI at RSAC 2025, introducing a new approach to autonomous security operations. Learn how this technology enables faster response and smarter defense